Contributing Content to ProtoWeb
Join our discord channel, or Facebook group ProtoWeb User Group. Ask one of the admins to help you get started.
As a volunteer to ProtoWeb, you must adhere to ProtoWeb Standards and agree to the terms and conditions of the User Agreement.
Quick Access
You Will Need
- Knowledge of HTML code
- Be able to run more than one web browser on your main computer specifically for testing, such as RetroZilla
- PuTTY
- Various web browsers to test recovered websites
Getting started
- You need two logins. One for the Contributor Panel and one for SSH. Contact Admins to get them. Tell the Admins your preferred username.
- Login to Contributor Panel
- Install and run the latest version of PuTTY
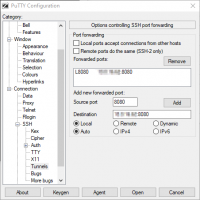
- In PuTTY, under Host Name type in sirius.steptail.com. Under Port, type in 2269
- On the navigation bar to the left, change to SSH and select the subcategory Tunnels.
- Under Source Port, type in 8080. The IP for the development server evolves over time, so it is best you ask for it in the Discord channel. You will type in the address in the following format: x.x.x.x:8080, where the x.x.x.x is the IP address of the development server. Make sure the option Local is selected, then click Add.
- On the navigation bar to the left, go back to the Session at the very top.
- You may save your settings now by typing in a name under Saved Sessions and clicking Save.
- Click Open to login. Type in your SSH username and password given to you in the earlier part of this guide.
- Once logged in, you will need to install and open up a alternative web browser, such as RetroZilla.
- Set your web browser proxy parameters as follows:
- HTTP: localhost, Port 8080
- FTP: localhost, Port 8080
- This will set the proxy server to the development server, so you can immediately preview the changes you've made to a website you are working on.

Contribution Workflow
The standard workflow is as follows:
- Decide which website you'd like to archive. Follow the Content Guidelines to see if the website you are planning to restore fits these guidelines.
- First open archive.org track down a good archived copy of a website domain. Browse the dates back and forth until you see a page with minimal amount of missing pictures, broken links or other errors. Note the date you've chosen. This date will be your target starting date for the archiver.
- Open the Contributor Panel and select “Archive web site”. Select a domain and target date as noted earlier. Select a link depth that is realistic for the website. If it's a large website, it could take days to complete with depth=6. If the website has an initial landing page or a “welcome” page with just one link to enter the main site, you may add +1 to the depth setting.
- Once archiving is complete, you will see the page under Completed Jobs and next to your completed job you will see an “Edit” button. This button allows you to access the file manager so you can edit the website. Any changes you make can be previewed using the development proxy server. The proxy server works just like the production server, except you're able to browse your changes immediately, and throttling is disabled. The development server will also download pages from archive.org “on the fly”, if a page does not exist while browsing the site you are trying to restore. This may be useful if you're validating all the links on a page and notice missing pages - automatic downloading ensures that you do not have to manually locate a file from archive.org.
- You will want to fix any broken links, and images. Once you're done, you can hit publish. The website will be marked published, and be viewable in the production server within 24 hours.
- Also, if the archive job failed for whatever reason, feel free to delete it and start over.
Questions Answered
Q: How do I know if my job has completed or failed?
A: You can view running jobs in the Contributor Panel, and looking at the job logs of your project will usually indicate if a failure has occurred. If you notice the archival job is still running, but you have made an error, you can delete a running job and start over.
Q: What if a recovered site is broken?
A: This depends. If the page is too far gone, and you cannot reconstruct the start page, we recommend you delete the site and find an alternative date with less broken links or images. If most of the pages are fine, you can fix some problems on a site manually, and missing graphics can be reconstructed. Sometimes you may find a file or a graphic that is missing but an alternative resource on archive.org or somewhere else on the net is available. In this case you can use the Upload URL feature in the File Manager which fetches a file from the Internet to the directory you specify. If portions of the website are not available anywhere, the links leading to broken areas of the websites may be commented out, so that the user is not presented with broken links. Do leave the HTML code in though, but comment it out. The hope is that eventually some broken areas can be restored with new restoration techniques.
Q: In the logs, it looks like archiving has slowed down. Is it stuck?
A: Toward the end of an archival process, the archiver goes through a lot of files and links trying to find any files that it may have missed. This is probably what you are seeing. Give it time - it will complete.
Q: I cannot access the web site I just crawled on the development server. The job is Complete, but I'm always getting a 500 server error!
A: The development server expects exact addresses. “www.site.com” is different than “site.com”. So make sure you are accessing the site with the URL you crawled. In other words, if you crawled “www.site.com”, then you will access the site as “www.site.com”. If you crawled “site.com”, then you will access the site with “site.com”. Only after publishing, the redirects will be added, so “site.com” will go to the primary site “www.site.com” and vice versa.
Q: I prefer working on site files on my own computer with my own text editors. Is this possible?
A: Affirmatively yes! once you have archived a website, you will need go back to the job queue, click on “Edit” to access the File Manager. Inside the File Manager, you may easily compress a website into a zip-file by selecting all files and then choosing “Zip”. This will begin a process in the background and the file manager will be unavailable until the compression of files is done. Zipping may take a few minutes. Once the process is complete, the file will appear in the active directory. You may then download the zip-file and unzip it to your computer to work on the files. Once you are done, you can create another zip archive, upload it back to the server. Then inside the File Manager, open the archive you uploaded, and click UnZip. You do not need to zip up a site every time you make a change. You may also upload individual edited files if you prefer. If you'd like to test the site on your local computer, you may choose to use a locally running HTTP server, or you can upload files to the development server and test the site there.
Q: I would like to back up the site I crawled. Is that possible?
A: Yes, you can always back up your site, even after you fix and edit it. Just log on to the Contributor Panel, go to the File Manager of the your website using the Edit button, select all files, and click on the ZIP or TAR buttons to create archives of the selected files. You can then download the archive to your computer.
Q: Can I capture specific URL's such as website subdirectories or specific files?
A: While this feature is planned to be added in the future, it is not currently available. If you need to add files to an existing site, you can upload them through the file manager, or use the Upload URL in the file manager to upload a link to a working file. If you need further assistance, contact one of the admins, and they will be able to modify the site files any way needed.
Questions? Comments?

